
|
|
latest version v1.9 - last update 10 Apr 2010 |
|
the parameters for the class MLP More...
#include <ltiMLP.h>
Public Types | |
| enum | eTrainingType { SteepestDescent, ConjugateGradients } |
Public Member Functions | |
| parameters () | |
| parameters (const parameters &other) | |
| virtual | ~parameters () |
| const char * | getTypeName () const |
| parameters & | copy (const parameters &other) |
| parameters & | operator= (const parameters &other) |
| virtual classifier::parameters * | clone () const |
| virtual bool | write (ioHandler &handler, const bool complete=true) const |
| virtual bool | read (ioHandler &handler, const bool complete=true) |
| bool | setLayers (const int hidden, const activationFunctor &activ) |
| bool | setLayers (const activationFunctor &activ) |
| bool | setLayerActivation (const int layer, const activationFunctor &aFct) |
Public Attributes | |
| eTrainingType | trainingMode |
| bool | batchMode |
| double | momentum |
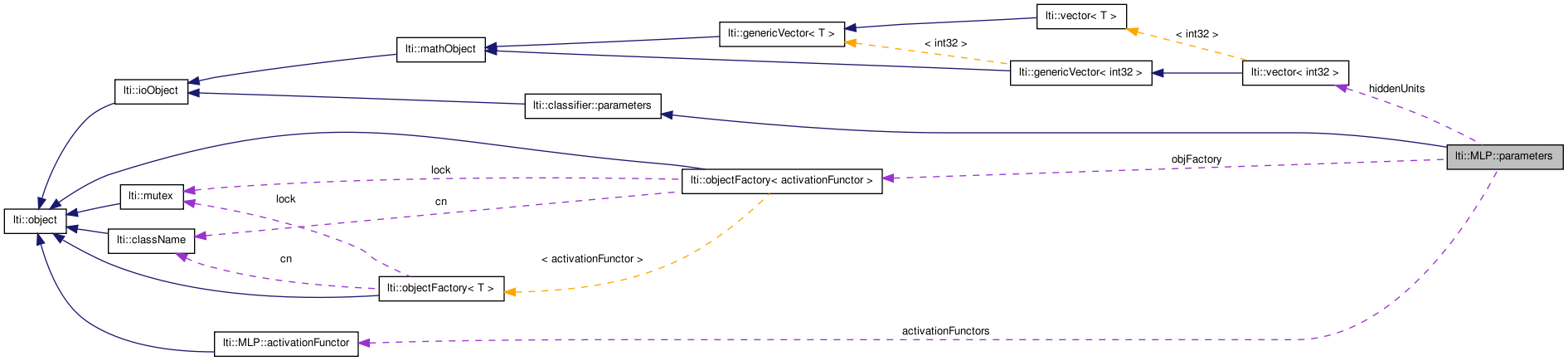
| ivector | hiddenUnits |
| float | learnrate |
| int | maxNumberOfEpochs |
| double | stopError |
| std::vector< activationFunctor * > | activationFunctions |
the parameters for the class MLP
| lti::MLP::parameters::parameters | ( | ) |
default constructor
Reimplemented from lti::classifier::parameters.
| lti::MLP::parameters::parameters | ( | const parameters & | other | ) |
copy constructor
| other | the parameters object to be copied |
| virtual lti::MLP::parameters::~parameters | ( | ) | [virtual] |
destructor
Reimplemented from lti::classifier::parameters.
| virtual classifier::parameters* lti::MLP::parameters::clone | ( | ) | const [virtual] |
returns a pointer to a clone of the parameters
Reimplemented from lti::classifier::parameters.
| parameters& lti::MLP::parameters::copy | ( | const parameters & | other | ) |
copy the contents of a parameters object
| other | the parameters object to be copied |
| const char* lti::MLP::parameters::getTypeName | ( | ) | const [virtual] |
returns name of this type
Reimplemented from lti::classifier::parameters.
| parameters& lti::MLP::parameters::operator= | ( | const parameters & | other | ) |
copy the contents of a parameters object
| other | the parameters object to be copied |
| virtual bool lti::MLP::parameters::read | ( | ioHandler & | handler, | |
| const bool | complete = true | |||
| ) | [virtual] |
read the parameters from the given ioHandler
| handler | the ioHandler to be used | |
| complete | if true (the default) the enclosing begin/end will be also written, otherwise only the data block will be written. |
Reimplemented from lti::classifier::parameters.
| bool lti::MLP::parameters::setLayerActivation | ( | const int | layer, | |
| const activationFunctor & | aFct | |||
| ) |
set the activation functor for a given layer.
The current number of layers is determined by the size of the hiddenUnits attribute.
| layer | number of layer | |
| aFct | activationFunctor |
| bool lti::MLP::parameters::setLayers | ( | const activationFunctor & | activ | ) |
initialize the parameters to create a MLP with one sigle layer (the number of input and output units is determined in the training stage).
| activ | activation function to be used in all units |
| bool lti::MLP::parameters::setLayers | ( | const int | hidden, | |
| const activationFunctor & | activ | |||
| ) |
initialize the parameters to create a MLP with two layers with the given number of hidden units (the number of input and output units is determined in the training stage).
| hidden | number of hidden units | |
| activ | activation function to be used in all units |
| virtual bool lti::MLP::parameters::write | ( | ioHandler & | handler, | |
| const bool | complete = true | |||
| ) | const [virtual] |
write the parameters in the given ioHandler
| handler | the ioHandler to be used | |
| complete | if true (the default) the enclosing begin/end will be also written, otherwise only the data block will be written. |
Reimplemented from lti::classifier::parameters.
| std::vector<activationFunctor*> lti::MLP::parameters::activationFunctions |
Activation functors (per layer).
The objects pointed by these elements will be deleted when the parameters are delete.
Default value: sigmoids
If true, an epoch (all the training data) will be presented before a weigh adaption is taken.
Otherwise just training point is considered to adapt the weights. For the conjugate gradient method this mode is ignored (assumed true).
Default value: true
Number of units in the hidden layers.
The size of this vector determines indirectly the number of layers for the network. It corresponds to is the number of layers minus one, which means that the total number of layers for the network is equal to the size of this vector plus one.
Default value: [4] (i.e. a 2 layer network with 4 units in the hidden layer)
Learning rate for the steepest descent method.
Maximal number of epochs (number of presentations of the entire training set).
Default: 500
Value for the momentum used in the steepest descent methods.
Should be between 0.0 and 1.0.
Default value: 0.0 (no momentum)
If this error value (or lower) is reached, the training is stopped.
For the conjugate gradients method, the algorithm is stopped if the magnitude of the gradient is smaller than this value multiplied by the magnitude of the initial gradient.
Default value: 0.005
Traning mode to be used.
Default value: ConjugateGradients